
In supply chain management, data and its targeted analytics are necessary to make statements about important influences on the supply chain: Which deliveries are often uncertain? Which materials or products are frequently delayed or how does their demand and inventory behave?
But if you want to use data from different sources for complex analyzes, you first have to collect the data and prepare it for analytics. For this you need data from different systems. In most cases, these systems are not only separated from one another, but also have different data storage systems, different database types, structures and flat files that require a process in order to combine the data into a meaningful overall view.
But what exactly does this “supply chain” of data in companies look like?
The preparation
In most companies, there is a big amount of data available in various systems such as ERP or CRM, and this amount of data is already growing immensely due to increasing digitalization. So let’s start with the preparation of the data. The data is usually processed in a so-called ETL process. The ETL process involves several individual steps, through which data from different sources can be integrated into a data warehouse by means of extraction and preparation.
The described process is often used to process big data in the business intelligence environment, as is increasingly required in supply chain management. The abbreviation ETL stands for the three terms Extract, Transform and Load. The aim is to prepare and provide the integrated data for further processing. The processing of large data volumes especially benefits from the structured ETL approach. If information is distributed on different subsystems, is redundant or has a different structure, the application of the ETL process is useful. During the process, the heterogeneously structured data from different sources is merged and prepared. The quality of the data is ensured, and its consistency is established in the data warehouse. I will come back to the importance of the data warehouse in the supply chain of data later in this article.
The ETL process is divided into three different phases. These phases are:
Extract: The first step is the extraction of the data from the different data sources. This involves selecting the data in the different source systems and preparing it for the transformation phase. In most cases, the process extracts only partial areas from individual source databases. Extractions take place on a regular basis to continuously supply the data warehouse with updated data. Event-driven or request-driven extractions are also possible.
Transform: The supplied data is adapted to the format and schema of the target database. The transformation process again passes through several individual steps. These individual steps can include, for example, the definition of basic aspects of formatting, the cleansing of erroneous data or the checking for similar information and duplicate data with subsequent deletion and exclusion.
Load: The final step of the ETL process is loading the transformed data into the target database or data warehouse. In this step the actual integration into the target database or data warehouse takes place. The data is physically moved to the target without blocking the database for a long time during loading. All changes in the target system are documented by detailed logging.
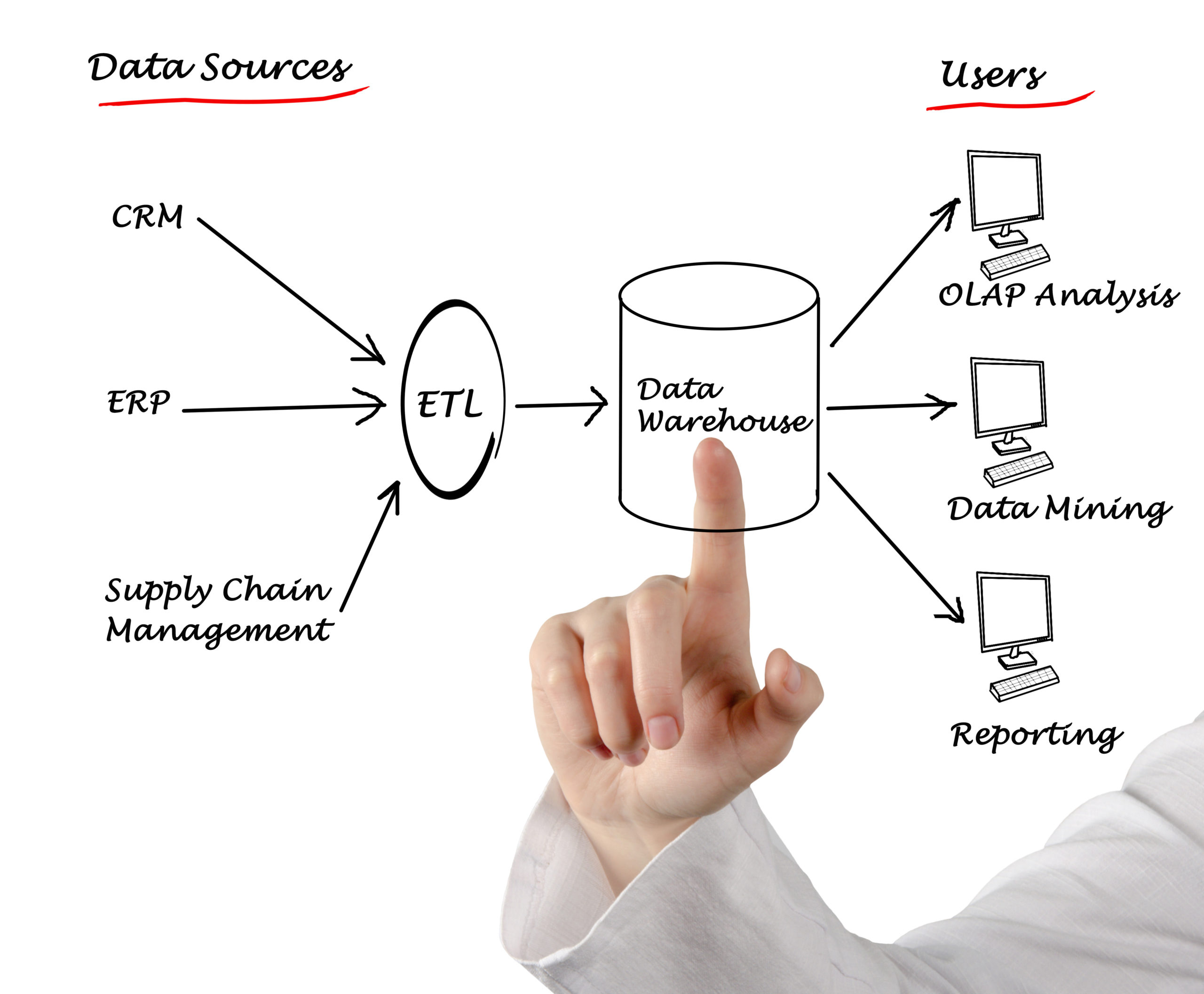
Image: (C) Getty Images – vaeenma
More and more companies are opting for an ELT strategy (Extract, Load, Transform – or Schema on Read), in which the transformations are carried out during the query and both structured and unstructured data are saved in raw format. The load and transform steps are swapped here. This is because the three individual steps do not always have to take place in the described order. The ELT process first loads the data into the target database without transforming it. All collected data is available in its raw form. This results in a so-called data lake, which consists of data in various formats. The transformation takes place in the target system with special procedures and algorithms only for the evaluations to be performed. This procedure offers the advantage that data can first be collected in the target system and made available for the evaluations.
The Data Warehouse
The point where everything comes together and the data is transported to is the data warehouse. A major problem of data warehouse architecture is the labor-intensive creation and operation of the ETL routes to fill the data warehouse systems. If changes are made to the source system, this results in a multitude of activities and programming efforts in the downstream systems. However, data warehouse automation tools allow data marts to be created automatically, and for data to be transferred live to the cloud using the change data capture process. This drastically reduces the manual effort involved in creating and maintaining ETL paths.
Data analytics in supply chain management are often very agile. There are always new requirements or new questions that need to be answered. In the worst case, the ETL process may have to be adapted or a new one created. This is where a data warehouse comes into play. Here, too, ETL processes are still necessary to transport the data from the source systems to the data warehouse. However, once these processes are established, they rarely need to be adapted. The data remains collected in the data warehouse and can be further modeled from there and used for connected data analytics solutions. The result is clear key figures that provide a real-time overview of important events or possible changes. Data science solutions, which for example improve data quality with the help of Machine Learning, can also build on this.
Closing Thoughts
Data is the most important indicator for making safe and correct decisions in supply chain management. But you cannot just use them without preparation. Data also has a supply chain from the source system to the respective evaluation. This management of data should be dealt with in good time in order to be able to turn data into corporate success in the long term. In my opinion, companies can only be successful if they make the right data-based decisions.
If you have further interest in this topic, visit the INFORM DataLab.
Image source: (c) Getty Images – Ioops7
2 comments
That is a good tip particularly to those new to the blogosphere. Brief but very precise info… Thanks for sharing this one. A must read article!
whoah this blog is wonderful i love reading your articles. Keep up the great work! You know, a lot of people are looking around for this info, you can help them greatly.
Comments are closed.